Digitised documents, i.e. documents originally created in physical form (paper, parchment, papyrus) and then digitised as images, have until now been difficult to exploit with information extraction algorithms. Written text, whether handwritten, typed or printed, has proved difficult to recognise automatically, due to the variety of styles, languages and content.
Over the past 10 years, handwriting recognition systems have made spectacular progress and these technologies now provide usable transcriptions, as evidenced by recent massive transcription projects in archival services, e.g. at the Dutch National Archives or for research projects such as the e-Baslac project.
The latest artificial intelligence models, based on Transformers, are again revolutionising the processing of digitised documents. Here is why.
A cascading processing chain
Until now, a standard processing chain for extracting information from scanned documents consisted of different steps:
- analysis of the page structure
- detection of text lines
- handwriting recognition
- extraction of named entities
The implementation of this chain required manual annotation of documents for each of these steps, using dedicated interfaces like Transkribus, eScriptorium or Callico. This annotation step was the most time-consuming and resource-intensive. Once the training data was available, the different models were trained and then applied sequentially to process the whole set of documents.
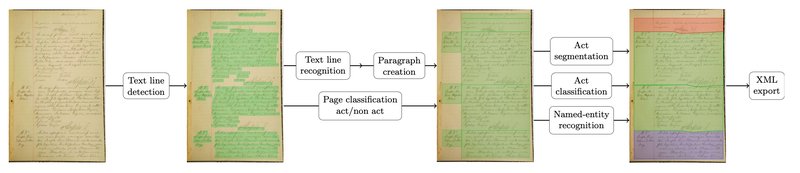
If the performance at the end of the chain was not sufficient, due for example to an accumulation of cascading errors, the improvement of the global system required the production of new annotated data for each of the stages, with once again the use of annotation platforms and the need for significant human resources.
Information extraction with a integrated single model
Recent models of artificial intelligence are completely challenging cascading processing chains. Indeed, thanks to the use of Transformer models, it is possible to train a single model to detect lines of text, recognise handwritten or printed text and extract entities. This type of model has the following advantages - a significant reduction in annotation time as it is no longer necessary to annotate line positions, transcribe text and tag entities. It is sufficient to provide the data to be extracted for each image during training; - a simplification of the processing chain: only one model to train and maintain in production; - the possibility of iteratively improving the model during the production phase, using the corrected or manually validated data, which was only possible with the standard chain, with new specific annotations for each model.
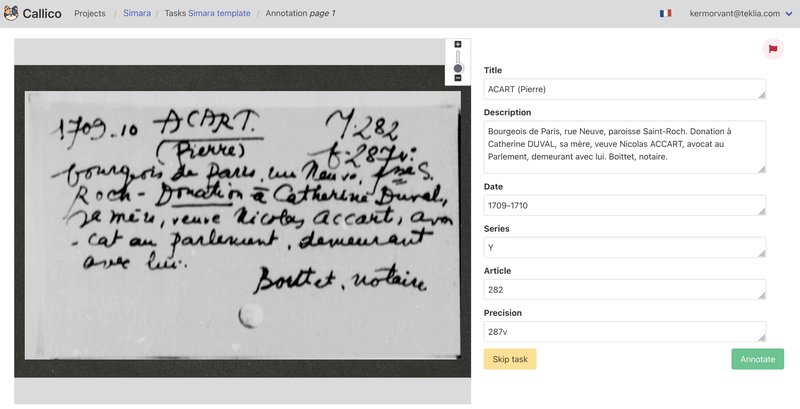
These models thus make it possible to simplify the implementation and execution of information extraction projects. TEKLIA has recently implemented a project with this type of model for the processing of 800,000 handwritten records at the Achives Nationales de France.
Two main types of information extraction
Projects for the automatic processing of digitised documents now fall into two main categories - transcription projects, which aim to enable full-text searches in documents - information extraction projects, which aim to extract a list of pre-defined data from documents.
In the case of transcription projects, generic handwriting recognition models of the type ATR (Automatic Text Recognition) may be sufficient for the needs of a textual search. If the generic models are not suitable, it is then necessary to train a specific model. To know if your documents can be processed with generic models, try our ATR demo.
In the case of information extraction projects, there are currently no generic models that can extract any data from a digitised document. It is therefore always necessary to train specific models.
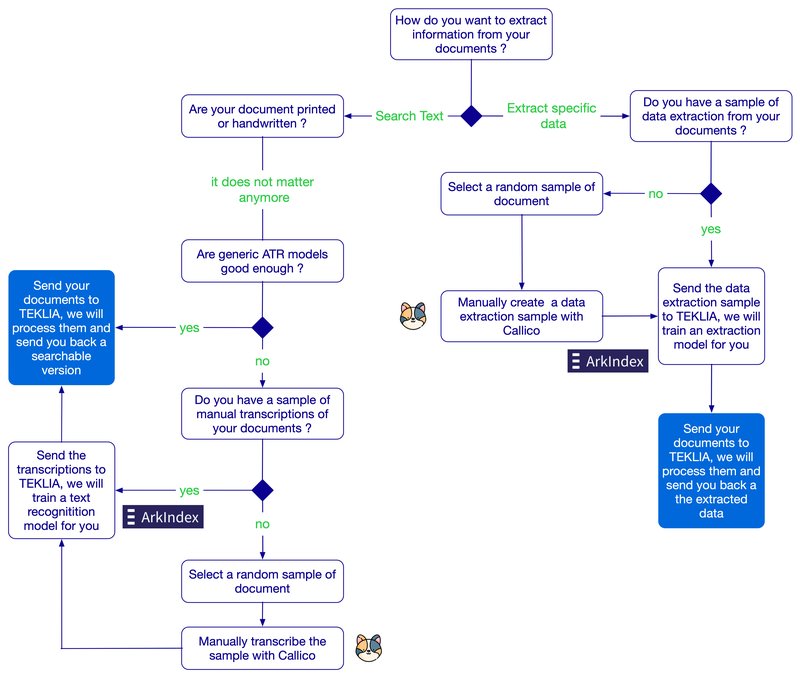
The decision tree below presents these different cases and the progress of projects carried out with TEKLIA thanks to its tools Callico for annotation and Arkindex for model learning:
You have text documents you would like to process, give it a try thanks to our Ocelus demo, at ocelus.teklia.com.
Do you want to index your collections or extract specific information to enrich the metadata of your documents? Contact us