Les documents numérisés, c'est-à-dire créés initialement sous forme physique (papier, parchemin, papyrus) puis numérisés sous forme d'images, ont jusqu'à présent été difficiles à exploiter avec des algorithmes d'extraction d'information. L'écriture, qu'elle soit manuscrite, dactylographiée ou imprimée, se révèlait difficile à reconnaitre automatiquement, de part la variété des styles, des langues et des contenus.
Depuis 10 ans, les progrès des systèmes de reconnaissance d'écriture ont été spectaculaires et ces technologies fournissent desormais des transcriptions exploitables, comme en témoignent les récents projets de transcription massive dans les services archives, par exemple aux Archives Nationales des Pays-Bas ou pour des projets de recherche universitaires comme le projet e-Baslac.
Les modèles d'intelligence artificielle les plus récents, à base de modèles Transformers, viennent à nouveau révolutionner le traitement des documents numérisés. Voici pourquoi.
Chaîne de traitement en cascade
Jusqu'à présent, une chaine de traitement standard pour l'extraction d'information dans les documents numérisés était composées de différentes étapes:
- analyse de la structure de la page
- détection des lignes de texte
- reconnaissance d'écriture
- extraction d'entités nommées
La mise en oeuvre de cette chaine nécessitait d'annoter manuellement des documents pour chacune de ces étapes, en utilisant des interfaces dédiées comme Transkribus, eScriptorium ou Callico. Cette étape d'annotation était la plus couteuse en temps et en ressources humaines. Une fois les données d'entrainement disponibles, les différents modèles étaient entrainées puis appliqués séquentiellement pour traiter l'ensemble des documents.
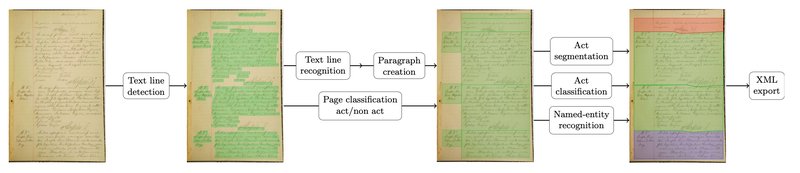
Si les performances en fin de chaine n'étaient pas suffisantes, à cause par exemple d'une accumulation d'erreur en cascade, l'amélioration du système global nécessitait la production de nouvelles données annotées pour chacune des étapes, avec une nouvelle fois un recours aux plateformes d'annotations et la nécessité de ressources humaines importantes.
Extraction d'information par un modèle unique
Les modèles récents l'intelligence artificielle remettent complètement en cause les chaînes de traitement en cascade. En effet, grâce à l'utilisation de modèles Transformers, il est possible d'entrainer un unique modèle pour à la fois détecter les lignes de texte, reconnaître le texte manuscrit ou imprimé et extraires les entités. Ce type de modèles présente les avantages suivants:
- une réduction importante du temps d'annotation car il n'est plus nécessaire d'annoter les positions des lignes, de transcrire le texte et de tagger les entités. Il suffit de fournir pour chaque image, lors de l'entrainement, les données à extraire;
- une simplification de la chaine de traitement: un seul modèle à entrainer et à maintenir en production;
- la possibilité d'améliorer itérativement le modèle lors de la phase de production, en utilisant les données corrigées ou validées manuellement, ce qui n'était possible, avec la chaîne standard, qu'avec de nouvelles annotations spécifiques pour chaque modèle.
Ces modèles permettent ainsi de simplifier la mise en place et la réalisation de projets d'extraction d'information. TEKLIA a récemment mis en place un projet avec ce type de modèles pour le traitement de 800 000 fiches manuscrites aux Achives Nationales de France.
Deux grands types d'extraction d'information
Les projets de traitement automatique de documents numérisés se décomposent désormais en deux grandes catégories:
- les projets de transcription, qui visent à permettre une recherche plein texte dans les documents;
- les projets d'extraction d'information, qui visent à extraire des documents une liste de données pré-définies.
Dans le cas des projets de transcriptions, des modèles génériques de reconnaissance d'écriture de type ATR (Automatic Text Recognition) peuvent être suffisants pour les besoins d'une recherche textuelle. Si les modèles génériques ne sont pas adaptés, il est alors nécessaire d'entraîner un modèle spécifique. Pour savoir si vos documents peuvent être traités avec un modèle générique, faites le test en ligne.
Dans le cas des projets d'extraction d'information, il n'existe pas à l'heure actuelle de modèles génériques permettant d'extraire n'importe quelle donnée à partir d'un document numérisé. Il est donc toujours nécessaire d'entraîner des modèles spécifiques.
L'arbre décisionnel ci-dessous présente ces différents cas et le déroulement des projets menés avec TEKLIA grâce aux outils Callico pour l'annotation et Arkindex pour l'apprentissage des modèles:
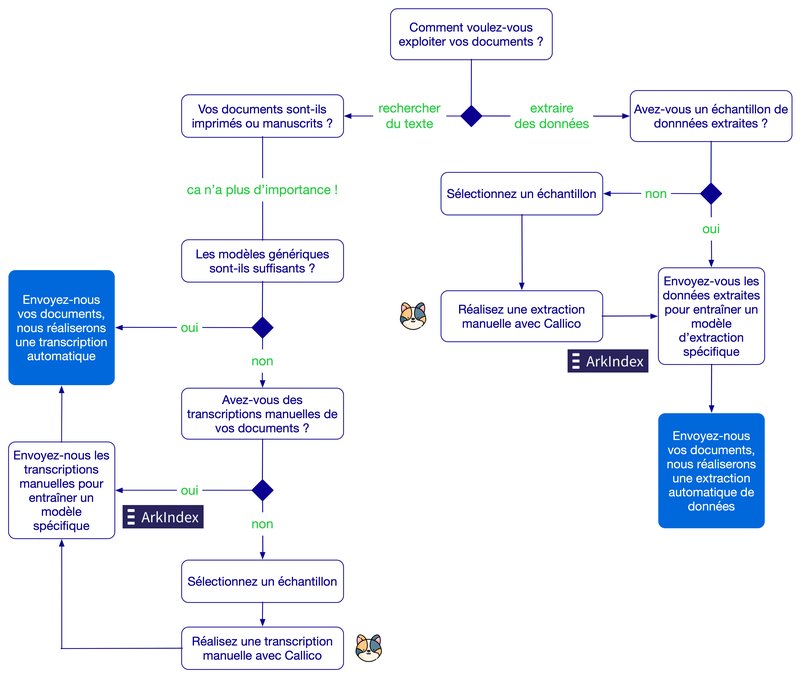
Vous souhaitez indexer vos collections ou extraire des informations spécifiques pour enrichir les méta-données de vos documents ? Contactez-nous !