Being able to process textual documents automaticaly has long been a challenge for Artificial Intelligence researchers. When dealing with text recognition from document images, multiple elements need to be considered, and especially for historical documents. These are mainly handwritten and can present complex layout. Until now, two different technnologies have been developed to perform text recognition: OCR (Optical Character Recognition) and HTR (Handwritten Text Recognition). Although both are meant to detect, identify and recognise texts, they operate in different ways.
A short history of OCR and HTR
OCR, the premises of Automatic Text Recognition
Optical Character Recognition, or OCR, was the first type of systems developed for text recognition. These systems are called optical because they based their recognition only on the analysis of characters' shapes and did not take into account the linguistic aspects of the words and sentences. They are trained to recognise the shape of each character in many fonts. They produce good results if the characters can easily be isolated, the font is standard and the scanning quality good enough.

When these conditions are not met, performance deteriorates rapidly and the generated text lacks consistency:

In this example, the font of the B (first letter of Benjamin) is atypical and distorted, the OCR recognises a W instead. Without context information, the d' is recognised as an @ and the à as a 4. It seems obvious that linguistic information, at least the language of the text, could improve performance.
OCR systems reach their limits when the text to be recognised is no longer printed but handwritten: the characters are no longer easily separable and their shape is no longer standardised.

Consequently, the basic principle of OCR, which consists of recognising characters in isolation and from their shape doesn't bring enough precision to the process, since it is not meant to associate characters to recognise words and sentences.
OCR technology can still be extended to handwriting in one specific case: when the characters are well separated, in a script or hand printed writing:

This is called ICR, for Intelligent Character Recognition.
HTR, one step further to completing accurate text recognition
The first methods developed for handwriting recognition sought to perform recognition at the word level. These approaches were called HWR, for Handwritten Word Recognition. The first step was to segment lines of text into words. As this segmentation was not always trivial, word segmentation hypotheses had to be taken into account.
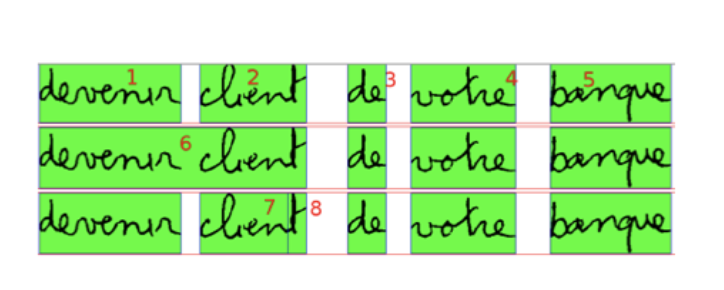
Once the words were isolated, the task was to recognise the letters in each word. A first approach was to try to segment the cursive word into elementary components, the graphemes. The objective was then to recognise each grapheme and then to reconstruct each letter from the identified graphemes.
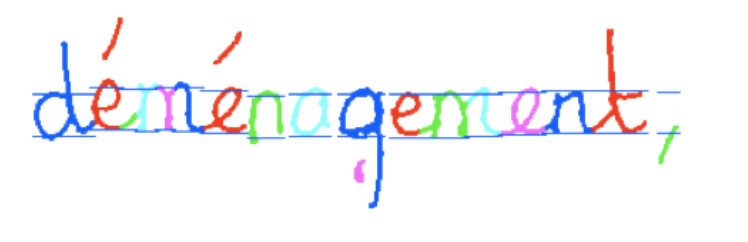
The difficulties encountered by this approach were numerous: difficulty in segmenting the graphemes, accumulation of errors on the different segmentation and recognition levels and finally a very high cost for the creation of training data: the positions of the graphemes had to be annotated.
Inspired by speech recognition systems, models based on a sliding window segmentation have been proposed [2]. This approach radically simplifies the problem of segmentation into graphemes or characters and has allowed models to be trained on large databases with statistical models such as Hidden Markov Models (HMM) or hybrid-HMM with neural networks.

With this technology, the basic unit of handwriting recognition is no longer the word, but the line of text. This is now called Handwritten Text Recognition, HTR.
Handwritten Text Document, or HTR, offers more features and allows to solve many of the issues raised by OCR. HTR combines both Optical and Linguistic aspects. The objective of the optical model is to recognise words from their writing as they appear in the image. The optical model is trained on image of text lines collected and manually transcribed during annotation campaigns. The linguistic model aims to statistically model the word sequences of the language so that the system produces correct and probable sentences. This model can be trained on electronic text corpora and does not require images.
Beyond text line recognitionn
All the models presented so far require a crucial first step: the detection of the text lines. While good models exist for this step, models have also been proposed that do not require the prior detection of text lines but deal directly with paragraphs or pages. An example of how this type of model works is shown in the video below [3]:
Recent developments in Deep Learning attention models, based on Transformers, also make it possible to dispense with text line detection under certain conditions[4]. TEKLIA has already used this type of models for the SIMARA project.
Introducing Automatic Text Recognition (ATR)
Why a new concept for document processing ?
Over the past decade, with the development of deep learning algorithms, the field of automatic document processing has seen a convergence of different technologies: the boundaries between OCR for printed documents, HTR for handwritten documents and even recently with document analysis models (DLA) are blurring. The models recognise both printed and handwritten text and process lines or paragraphs. The old categories of OCR, ICR, HTR are no longer relevant.
We should now refer to Automatic Text Recognition, ATR.
Ocelus, our ATR service
Ocelus, Teklia's Automatic Text Recognition API, allows you to upload the image of document and to retrieve the full text transcription for printed, handwritten or mixed documents. Both generic and language specific models are available.
You have text documents you would like to process, give it a try thanks to our Ocelus demo, at ocelus.teklia.com.

References
[1] J.-C. Simon and O. Baret, "Regularities and Singularities in Line Pictures," in Structured Document Image Analysis, Berlin, Heidelberg: Springer Berlin Heidelberg, 1992, pp. 261–281.
[2] J. Makhoul, R. Schwartz, C. Lapre, and I. Bazzi, "A Script-Independent Methodology For Optical Character Recognition," Pattern Recognit., vol. 31, no. 9, pp. 1285–1294, 1998.
[3] Théodore Bluche, "Joint Line Segmentation and Transcription for End-to-End Handwritten Paragraph Recognition," in 30th Conference on Neural Information Processing Systems, 2016
[4] Denis Coquenet, Clément Chatelain, Thierry Paquet, "End-to-end Handwritten Paragraph Text Recognition Using a Vertical Attention Network", IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022.
- Archives parlementaires, Bibliothèque nationale de France. https://gallica.bnf.fr/ark:/12148/bpt6k480090t