Teklia are proud to announce that we have completed the work to process all the registers in the BALSAC project, which has been digitizing historical data on the Quebec population.
What is BALSAC?
The BALSAC project has been building a database of demographic events (birth, marriage and death records) of the Quebec population. The database is built by linking together the demographic events from transcribed parish registers. The database comprises about 2 million scanned images of (mostly) handwritten parish records from the second half of the 19th to the beginning of 20th century. Some examples of the pages needing processing appear below.

How has Teklia helped?
As one might expect, it is a lot of work to transcribe 2 million images manually. Fortunately, machine learning methods have become good enough, in recent years, to automate this process.
At Teklia, our goal was to develop a system capable of processing 2 million images, that can automatically transcribe the pages, segment them into acts, or records, detect entities, and in the end export the results as XML so they could be imported into the BALSAC database. The BALSAC team will integrate the exported records in the database and relying on nominative information will link them in order to reconstruct individual biographies and family histories.
To digitize a database of this size, we had to improve Arkindex by training different machine learning models and incorporate them into Arkindex.
Overview of the Machine Learning process
In the workflow figure below, we can see the dependencies between different machine learning steps. We've also outlined each step below the figure.
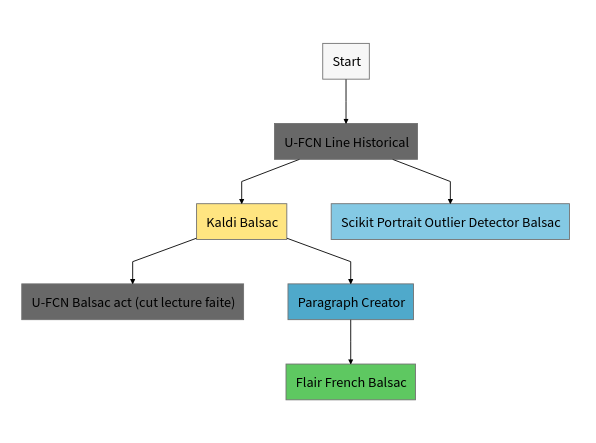
UFCN Line Historical- (Document Layout Analysis) Before doing anything, we need to detect the text lines on the image. To do that we use Doc-UFCN model trained on historical data including annotated data from BALSAC. You can read more about Doc-UFCN in a recent blog post.Kaldi Balsac- (Handwritten Text Recognition) We trained a Kaldi model on annotated BALSAC pages to transcribe text lines into machine-readable text.U-FCN Balsac act (cut lecture faite)- (Document Layout Analysis) We trained a model on BALSAC pages to segment a page into acts, or records (act_start,act_center,act_end,act). An act can either start on a page, end on a page or be fully contained on a page. In addition, the model will predict whether an act is about a birth, marriage or death based on common keywords for each type. Teklia's model is based on Doc-UFCN library, but extra textual information is included to improve the results. You can read more about our method in the paper we published: Including Keyword Position in Image-based Models for Act Segmentation of Historical Registers.Paragraph Creator- (Document Layout Analysis) We created a tool to concatenate lines together into paragraphs so the named entity recognition model would have more context and could produce better results.Flair French Balsac- (Named Entity Recognition) We trained a flair model on annotated BALSAC entities to detect person names, dates, locations, professions.Scikit Portrait Outlier Detector Balsac- (Outlier Detection) We created an outlier detection model using scikit learn based on the detected text lines to find pages that do not contain acts (or which look out of the ordinary), because we only had pages with acts in the annotated dataset.- Finally, we combined the predictions of different tools together to export each register as an XML file of acts.
Results
After completing the transcription and insertion into the BALSAC database, we were happy with the results. They are exemplified and summarized below.
Example

Text from the first full act recognized by our tool:
Le cinq juin mil neuf cent cinq , nous
prêtre curé soussigné avons baptisé Marie
Rose née le même jour , du légitime
mariage de Jean Boisvert et de
Adele Cloutier de cette paroisse . Pouvoir
François Cloutier marraine Arthémise
Beausoleil . Lesquels n ' ont su signer avec nous
Ed . Lessier ptre
Statistics
While processing images with our workflow we found out that sometimes our models perform worse on double pages. To deal with that we naively cut all the double page images in half, so in the end the number of processed pages is higher than the number of images (almost 2 million).
In the dataset we had 44 742 registers from 1 985 parishes. In total we had 2 635 038 single page images that contained 5 591 535 acts, 15 668 671 paragraphs and 111 270 929 text lines.
Count of elements by type on Arkindex of the BALSAC project:
| Type | Count | | -----------------|------------:| | act | 5 591 535 | | double_page | 638 467 | | page | 2 635 038 | | paragraph | 15 668 671 | | parish | 1 985 | | register | 44 742 | | text_line | 111 270 929 |
Count of entities by type on Arkindex of the BALSAC project:
| Type | Count | | ---------- |---------- :| | date | 8 655 893 | | location | 5 429 807 | | person | 30 986 429 | | profession | 4 624 291 |
The number of entities and the number of acts are consistent with our expectations. Each act has about 1-2 dates, about 1 location and about 5-6 persons. But we have to remember that some of those acts are incomplete (act_start, act_center, act_end) that either started on another page or will end on another page.
We are happy to have been able to process all these pages and deliver the exported results. It is an important step to show what is possible to do with Arkindex, and by further developing our tool on the BALSAC dataset, we've made Arkindex that much better for future historical datasets for import.