The Three levels of Processing for Historical Documents
While there have been significant advances in the field of Handwritten Text Recognition (HTR) by several players, including Transkribus and eScriptorium, the journey doesn't stop at mere text recognition. In this field, we've defined three levels of document processing, each providing an increasing level of information extraction. These approaches not only go beyond simple text recognition, but also provide comprehensive solutions that surpass previous achievements in the field. Let's explore these three levels of processing that are revolutionising the way historical documents are handled.
1. Transcription and indexing of handwritten documents
The first and most straightforward application of Automatic Text Recognition (ATR) technology is the transcription and indexing of handwritten documents. In this area, Handwritten Text Recognition (HTR) has demonstrated significant utility and robustness. Now a mature technology, HTR has been applied to millions of documents around the world.
The true strength of HTR lies in its versatility - it can handle all writing scripts, whether Arabic, Hebrew, Latin, Cyrillic or Hanzi, for languages both in their modern and historical forms. This comprehensive feature allows handwritten documents to be converted into searchable formats. This brings accessibility on a par with electronic and printed documents.
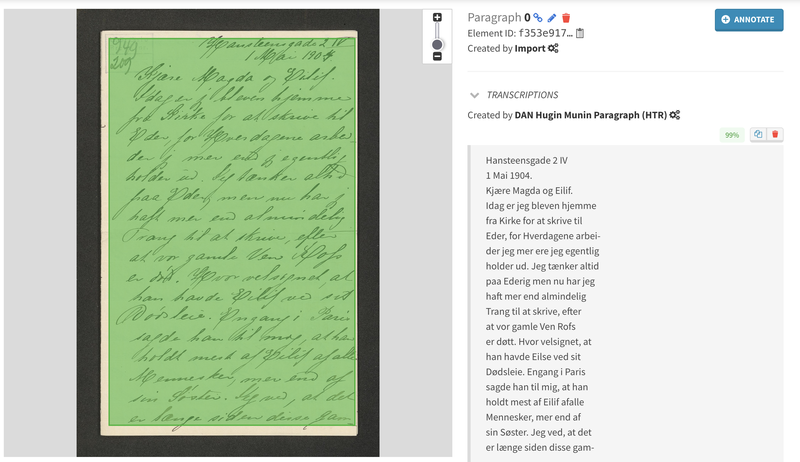
By developing an innovative approach using full-page HTR models, TEKLIA has taken this technology even further. These models eliminate the need for pre-detection of text lines, a common requirement in traditional HTR systems. By eliminating this step, the likelihood of error is reduced and the process of generating training data is greatly simplified. This breakthrough not only improves the accuracy of the transcription, but also increases the efficiency of the overall process.
More on multilingual Text Recognition
2. Information Extraction in Handwritten Documents
Building on the solid foundation of HTR, the next level of processing is information extraction in handwritten documents. This step represents an evolution in the processing of historical documents, as it goes beyond mere transcription to extract meaningful information within the text.
The recipe is to combine HTR with Named Entity Recognition (NER), an intelligent system that identifies and classifies key elements in a text, such as names, places or dates. TEKLIA has disrupted the conventional workflow by integrating semantic tagging into the full-page HTR system. This fusion allows to perform text line recognition, handwriting recognition and named entity recognition in a single step.

This sophisticated system also allows the automatic creation of indexes for historical documents, making navigation easier. It even facilitates the creation of databases from the documents, improving the organisation and accessibility of information.
Learn more about how we facilitated the conversion of handwritten finding aids for the French National Archives.
3. Handwritten table recognition
Handwritten tables, with their two-dimensional structures and intricate layouts, are among the most challenging documents to process automatically. Not only do they contain handwritten text, but the textual information is often split across two lines within a single cell or spread across multiple cells. Deciphering such complexity requires a deep understanding of the content, context and structure of the document.
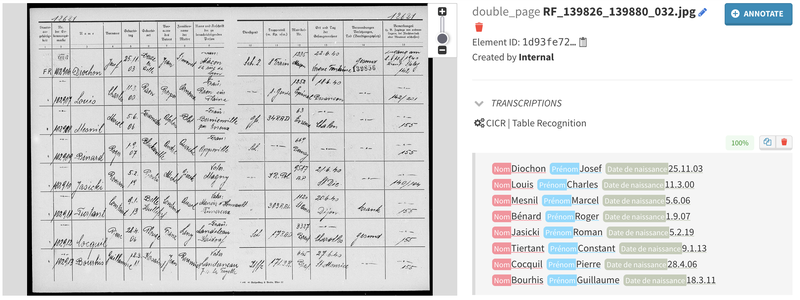
This is where TEKLIA's handwriting recognition comes in. Combining the power of full-page handwriting recognition and named entity recognition, TEKLIA's Handwritten Table Recognition not only captures the data within the table, but also understands its contextual meaning. What sets our approach apart is the unique, integrated model we use to manage the entire process.
This one-step approach dramatically simplifies the setup of the entire processing workflow, eliminating the need for multiple models or steps. By using a single model, we also reduce the likelihood of cascading errors, a common problem in multi-step processes.
This application opens up new vistas for researchers and historians, enabling efficient and accurate access to a wealth of structured information that was previously buried within the confines of handwritten documents.
Try TEKLIA's AI Today
Are you intrigued by the potential of our technology and how it could revolutionise your work with historical documents? Don't hesitate to contact us to arrange a trial run on your documents. Our team is ready to guide you through the process and show you how our innovative solutions can unlock the full potential of your historical documents.
Try our online recognizer for modern documents at http://ocelus.teklia.com. While this model is optimized for modern scripts, it can provide a baseline for the processing of historical documents. However, for optimal results with historical texts, we recommend using our customized models designed to handle their specific nuances and complexities.
- Try ocelus.teklia.com on-line
- Contact us today !