ICRC Archives

Founded in 1863, the International Committee of the Red Cross is an impartial, neutral and independent humanitarian organization dedicated to protecting the lives and dignity of victims of armed conflicts and other situations of violence, and to providing them with assistance.
ICRC archives hold documents produced by the organization or deposited by third parties. These archives represent 6,700 linear metres of textual documents. The archives department responds to numerous requests for information from the families of victims or prisoners of war.
To speed up the processing of requests for information, the archive department has launched a major digitization campaign. Some printed documents can also be automatically transcribed, but up to now, handwritten documents such as lists of World War II prisoners were beyond the reach of OCR.
In response to this challenge, the International Committee of the Red Cross entrusted TEKLIA with a pilot project to evaluate handwriting recognition technologies on its documents, and to test the use of collaborative transcription.
A hybrid approach: collaborative transcription and AI
Following an initial feedback with HTR (Handwritten Text Recognition in the ICRC WW2 Archives: Is it the magical solution? Michèle Hou, ICA 2022), TEKLIA proposed to ICRC to test a hybrid approach: automatic recognition using an integrated information extraction model (Handwritten Text Recognition and Named-Entity Recognition, HTR+NER) combined with an intuitive and efficient collaborative transcription interface, Callico.
The first stage of the project involved a double-keying annotation campaign carried out on a sample of 500 pages of handwritten lists of World War II prisoners, by a small number of ICRC archivists.
Traditionally, this type of annotation campaign involves detecting lines of text, transcribing them and tagging the information to be collected. The models developed by TEKLIA do not require all these steps: annotations simply involve filling in a form for each line of the tables in Callico. With this type of form-based annotation, the annotation process is much simpler and faster.
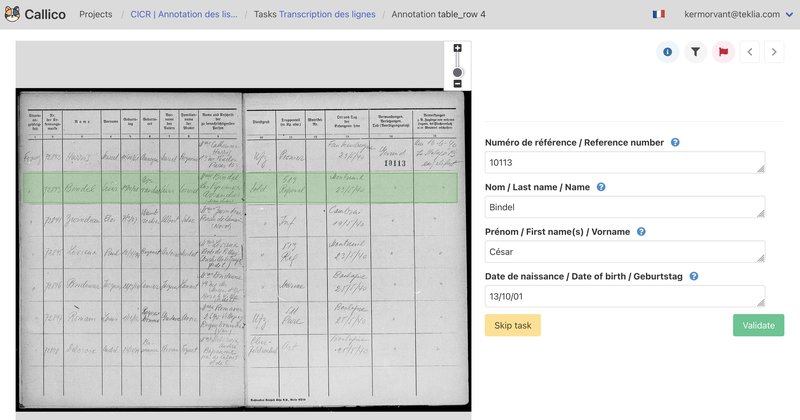
Annotating the 500 pages containing an average of 8 lines took around the 30 annotators 60 hours of work, or approximately 30 seconds per annotated line.
Training a recognition model for lists
The annotations made by the archivists served as training data for the development of a handwriting recognition model specifically designed to process handwritten lists, for the purpose of extracting nominative information (surname, first name, date of birth and RF number).
TEKLIA's HTR+NER integrated extraction models are able to perform handwriting recognition and identification of the information to be extracted in a single pass. These models are trained from the annotations of the information present on the complete page, without the need to locate them on the image. Once trained, the model is able to process a complete image, without prior detection of the table lines.

At the end of this first training phase, the recognition model had a character error rate of 8.8% on an independent test sample. Detailed extraction performances, measured with the F1 score of the Nerval library, were as follows:
- Surname recognition: 91%
- First name recognition: 86%
- Date of birth recognition: 85%
- RF number recognition: 97%
This model will now be used to automatically extract information from a batch of 5000 pages from the same database. The predictions will then be proposed to ICRC staff for collaborative validation in Callico, but this time the annotators will only have to check the information predicted by the model and correct it if necessary. The time required for validation will thus be reduced, especially as some of the predictions, for which the model is very confident, will not have to be validated.
See you soon for the conclusion of the project.
Are you looking for an effective solution for handwriting recognition on large volumes of handwritten documents? Contact us now, and we'll set up the same type of processing for your project!