Les archives du CICR

Créé en 1863, le Comité International de la Croix Rouge est une organisation humanitaire impartiale, neutre et indépendante qui a pour mission de protéger la vie et la dignité des victimes de conflits armés et d'autres situations de violence, et de leur porter assistance.
Le service des archives du CICR conserve les documents produits par l'organisation ou déposés par des tiers. Ces archives représentent 6700 mètres linéaires de documents textuels. Le service des archives répond ainsi à de nombreuses demandes de renseignements issues des familles des victimes ou prisonniers de guerre.
Afin d'accélérer le traitement des demandes d'information, le service des archives a lancé une grande campagne de numérisation. Certains documents imprimés peuvent aussi être transcrits automatiquement mais jusqu'à présent, les documents manuscrits comme les listes de prisonniers de la seconde guerre mondiale étaient hors de portée des OCR.
Pour répondre à ce défi, le Comité International de la Croix-Rouge a confié à TEKLIA un projet pilote pour évaluer les technologies de reconnaissance d'écriture sur ses documents, et pour tester l'utilisation de la transcription collaborative.
Une approche hybride : transcription collaborative et IA
Suite à un premier retour d'expérience avec l'HTR ( Handwritten Text Recognition in the ICRC WW2 Archives: Is it the magical solution? Michèle Hou, ICA 2022), TEKLIA a proposé au CICR de tester une approche hybride : la reconnaissance automatique par un modèle intégré d'extraction d'information (Handwritten Text Recognition et Named-Entity Recognition, HTR+NER) combiné avec une interface intuitive et efficace de transcription collaborative, Callico.
La première étape du projet a consisté en une campagne d'annotation en double saisie réalisée sur un échantillon de 500 pages de listes manuscrites de prisonniers de la seconde guerre mondiale, par un nombre restreint d'archivistes du CICR.
Traditionnellement, ce type de campagnes d'annotation nécessite de détecter les lignes de textes, de les transcrire et de tagguer les informations à collecter. Les modèles développés par TEKLIA ne nécessitent pas toutes ces étapes : les annotations consistent simplement à remplir un formulaire pour chacune des lignes des tableaux dans Callico. Grâce à ce type d'annotation par formulaire, le processus d'annotation est bien plus simple et rapide.
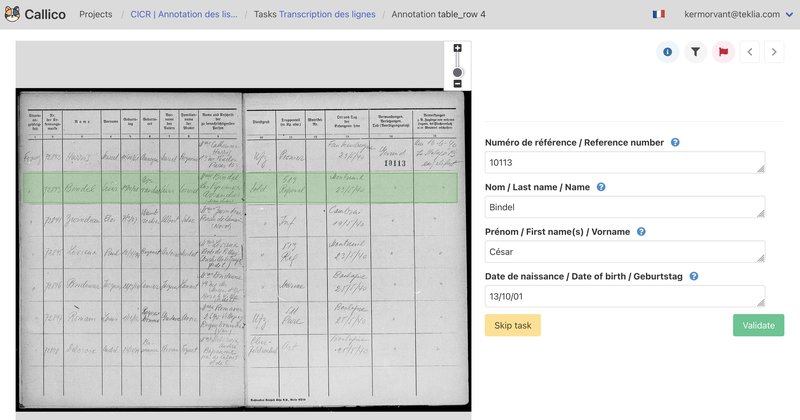
L'annotation des 500 pages comportant en moyenne 8 lignes a représenté un travail de 60 heures pour une trentaine d'annotateurs, soit environ 30 secondes par ligne annotée.
Entraînement d'un modèle de reconnaissance pour les listes
Les annotations réalisées par les archivistes ont servi de données d'entraînement pour la mise au point d'un modèle de reconnaissance d'écriture spécifiquement conçu pour traiter des listes manuscrites, en vue d'extraire des informations nominatives (nom, prénom, date de naissance et numéro RF).
Les modèles d'extraction intégrés HTR+NER de TEKLIA sont capables d'opérer en une passe la reconnaissance d'écriture et l'identification des informations à extraire. Ces modèles sont entrainés à partir des annotations des informations présentes sur la page complète, sans nécessiter leur localisation sur l'image. Une fois entrainé, le modèle est capable de traiter une image complète, sans détection préalable des lignes du tableau.

A l'issue de cette première phase d'apprentissage, le modèle de reconnaissance présente un taux d'erreur caractère de 8.8% sur un échantillon de test indépendant. Le détail des performances d'extraction, mesurées avec le F1 score de la librairie Nerval étaient les suivantes :
- reconnaissance du nom de famille : 91%
- reconnaissance du prénom : 86%
- reconnaissance de la date de naissance : 85%
- reconnaissance du numéro RF : 97%
Ce modèle va maintenant être utilisé pour extraire automatiquement les informations sur un lot de 5000 pages issues du même fond. Les prédictions seront ensuite proposées aux collaborateurs du CICR pour une validation collaborative dans Callico, mais cette fois, les annotateurs n'auront qu'à vérifier les informations prédites par le modèle et à les corriger si nécessaire. Le temps nécessaire à la validation sera ainsi réduit, d'autant plus qu'une partie des prédictions, pour lesquelles le modèle est très confiant, n'aura pas à être validée.
Rendez-vous prochainement pour la conclusion du projet.
A vous ?
Vous recherchez une solution efficace pour réaliser une reconnaissance d'écriture sur un volume important de documents manuscrits ? Prenez contact sans plus attendre, et mettons en place le même type de traitements pour votre projet !