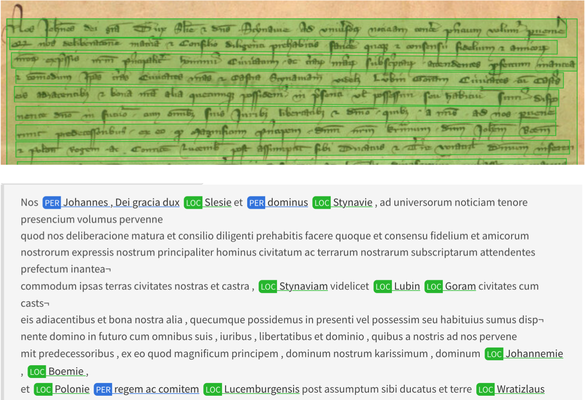
In this paper, we propose an evaluation of several state-of-the-art open-source natural language processing (NLP) libraries for named entity recognition (NER) on handwritten historical documents: spaCy, Stanza and Flair. The comparison is carried out on three low-resource multilingual datasets of handwritten historical documents: HOME (a multilingual corpus of medieval charters), Balsac (a corpus of parish records from Quebec), and Esposalles (a corpus of marriage records in Catalan). We study the impact of the document recognition processes (text line detection and handwriting recognition) on the performance of the NER. We show that current off-the-shelf NER libraries yield state-of-the-art results, even on low-resource languages or multilingual documents using multilingual models. We show, in an end-to-end evaluation, that text line detection errors have a greater impact than handwriting recognition errors. Finally, we also report state-of-the-art results on the public Esposalles dataset.