We are happy to announce that a new Arkindex release is available. You can explore Arkindex and try out the newest features on our demo instance, demo.arkindex.org.
This release was mainly focused on quality or performance improvements and bug fixes, to end the year on a good note.
Datasets
We continue to improve Machine Learning training datasets support into Arkindex.
Arkindex Elements can now be removed from a dataset from their details page, and not just from the dataset's details page.
Datasets marked as complete can no longer be modified. New versions of a complete dataset can easily be created to extend or modify it.
Renaming one set in a dataset now updates the set name for all elements belonging to that set. Renaming more that one set at a time is not longer allowed. Adding or removing any number of datasets at a time is still possible.
A link back to the project is now shown when browsing a dataset, to make navigation easier.
The listing of datasets when using the Add to a dataset action in the selection page has been fixed.
Workers
Workers now have a description field, allowing them to be better documented in the interface. That description, as well as other attributes on workers, can be edited through the API and the user interface, in the list of available workers.

Using the API, workers can also be marked as archived, which hides them from the available workers list and makes them impossible to use on processes. Future releases will include the option to archive or un-archive from the frontend itself, as well as support for an automatic removal of any archived workers that have not produced any existing worker results.
Worker versions can now be marked as supporting models without requiring them, just like a worker version can either support, require or not support GPU usage. Worker developers need to update their .arkindex.yml files to use the new model_usage values: required, supported or disabled.
Worker configurations can now include fields of a model type, allowing users to select a model. This can be useful when training models using dataset processes, in order to specify the model to train.
The display of archived worker configurations in the worker configuration modal has been fixed.
User configuration parameters are now sorted alphabetically by display name, rather than slug.
The workers list filter now displays all the available worker types, when it was previously limited to the first 20 types.
Models
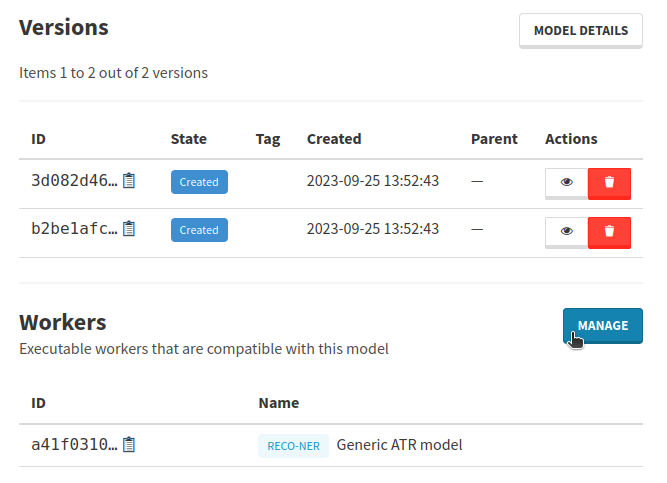
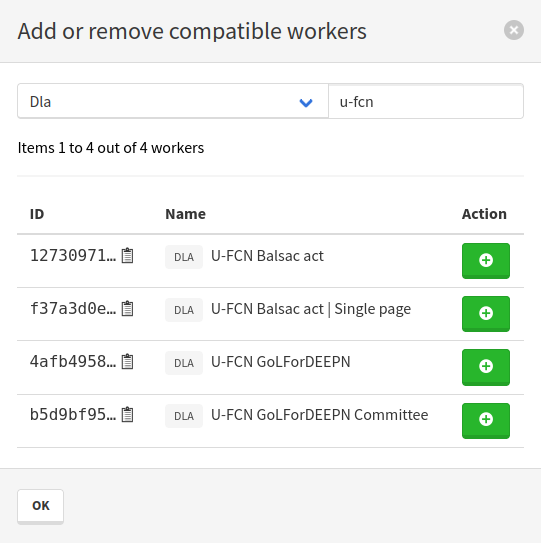
Workers declared as compatible for a model can now be viewed and managed through the API, using the new endpoints CreateModelCompatibleWorker and DestroyModelCompatibleWorker. They can also be managed from the user interface: in a workers section in the list of available models, or from the model details page.
Using the API endpoints UpdateModel or PartialUpdateModel, models can now be marked as archived, which hides them from the available models list and makes them impossible to use on processes. Future releases will include the option to archive or unarchive from the Arkindex frontend, as well as support for an automatic removal of any archived models that have not produced any existing worker results.
A model version's parent ID can now be unset, using the API or the Django admin.
The frontend interface to add new members to models has been fixed.
Performance
The ListTranscriptions API endpoint has been optimized, which should prevent timeouts when using the recursive, worker_version and element_type filters.
Processes
The project worker activities page has been removed, as it was both confusing and rarely used.
When creating a process from elements filtered by a classification, that classification filter is now propagated to the process elements list.


A record of the link between a task and the worker run it was created for is now being kept, so that when a task fails, only the worker activities of the relevant worker run are set to an error state.
Tasks now have restrictions on their state updates from Ponos agents, to warn about situations that should not be normally possible.
An issue that could prevent a process' worker runs from being listed on slow connections or slow instances was fixed.
Worker version created through the CreateDockerWorkerVersion API endpoint are not longer treated as unavailable when applying a template.
Attempting to delete a process whose worker runs are linked to existing worker results now shows an explicit error message, instead of causing database errors.
Imports
Importing PDF files from an S3 bucket now extracts the JPEG images of the PDF, instead of relying on Cantaloupe's PDF support. This improves performance for very large PDFs.
Transkribus archive imports no longer cause errors when importing PNG files.
The frontend file import now supports .zip and .tar.gz archive files.