We are happy to announce that a new Arkindex release is available. You can explore Arkindex and try out the newest features on our demo instance, demo.arkindex.org.
Datasets
This release includes further improvements to our new datasets feature. You can now browse the elements in a dataset and remove them through the frontend:
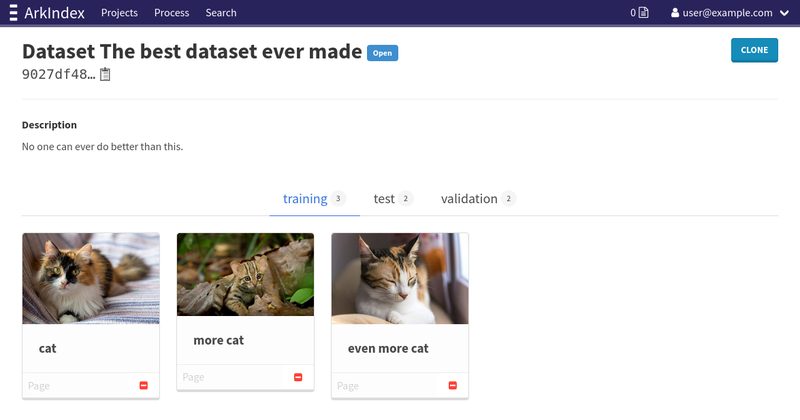
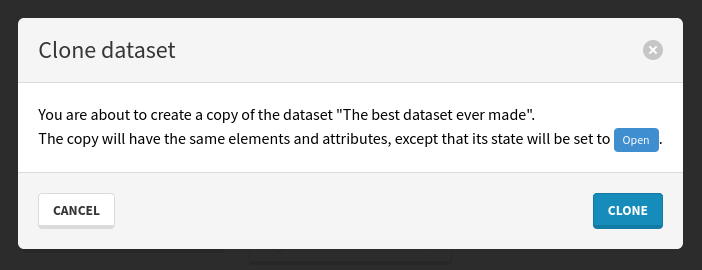
Since datasets are meant to be immutable once they have been built, they can only be edited when they are in an Open state. You can instead clone a dataset to get a new one you can edit again.
Datasets and dataset elements are now included in our SQLite exports. We also fixed some issues when deleting a project that has datasets, or deleting a dataset that has elements added to it.
Ponos tasks can now list and download all artifacts from any task that the creator of their process has access to, which enables workers running on dataset processes to download the artifacts of their datasets.
Transkribus imports
The Transkribus import feature has now been merged into file imports. Instead of having to give Arkindex access to your Transkribus collection to allow it to export the data by itself, you can now import the ZIP archives exported from Transkribus as files, just like how you can import images, PDF documents or IIIF manifests. You can learn more about this new procedure in our Transkribus import documentation.
Machine Learning models
Giving guest access to a model, or marking the model as being a public model through the Django admin, now allows a user to execute processes with all the versions on a model that are in an available state and with a tag. This allows for use cases such as a public demo of some models on an Arkindex instance with open registrations.
Additionally, two new endpoints, CreateModelCompatibleWorker and DestroyModelCompatibleWorker, are now available to allow ML model integrators to mark a model as being compatible with a specific worker, making it easier to pick the right models when creating processes.
Task execution
Ponos agents groups (also known as Farms) that run the tasks in your processes, now have access rights. Those rights can only be controlled through the Arkindex admin, as only instance administrators are meant to manage them. For example, you can now give some more privileged users access to a farm of more powerful but more expensive agents, and leave other smaller agents to everyone else.
Upgrading to this new Arkindex version will cause everyone, except instance admins, to lose access to every farm until they are granted access back.
Arkindex instance administrators can now configure their instance to assign a group to all users when they first register, making it easier to grant everyone access to a public farm.
Due to this change, the file and S3 imports, as well as training processes, now allow selecting a farm and will display errors related to lacking access rights to a specific farm.
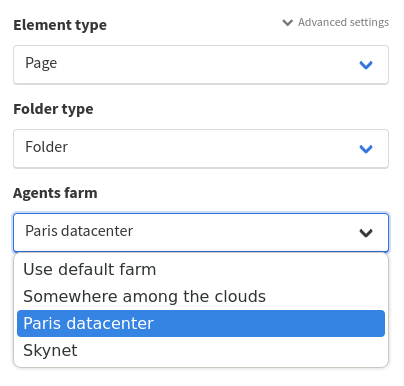
Additionally, a limit can now be defined in the Django admin to prevent an agent from getting too many tasks assigned to it at once.
Element management
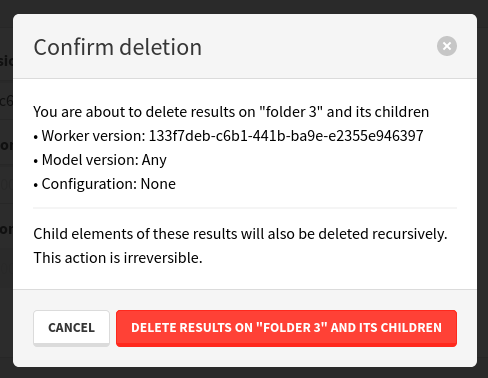
In the previous release, we had updated the worker results deletion modal to handle model versions and worker configurations. In the process, we had also removed the ability to use direct input, which was letting you type in the UUID of the worker version to delete. You can now switch the modal to Advanced mode to get this direct input back, allowing you to delete anything even when it is not in our cached list of worker result sources.
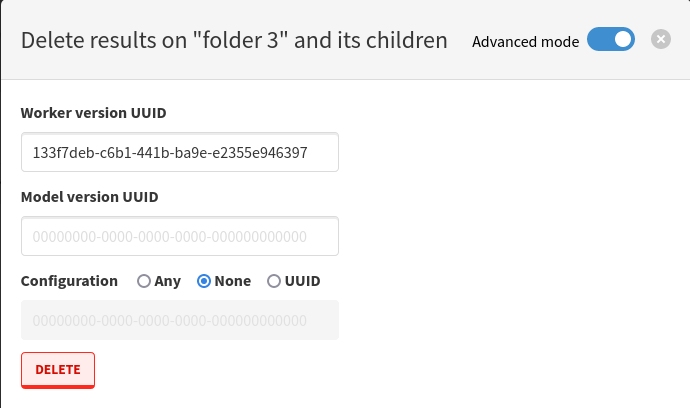
After making your selection, you will get a confirmation modal to verify that you selected the appropriate filters for your deletion.
User worker runs
Sometimes, you might want to perform batch processing on large amounts of data, but just once and in a very specific case, using a script calling our API. You might want to be able to differentiate between human inputs and your script, without having to create a worker, which can take a while and might not be flexible enough for your use case. We had provided two commands to instance administrators, arkindex fake_worker_version and arkindex fake_worker_run, that allowed to create a worker version and a worker run on a fake Git repository to allow scripts to use those IDs and identify themselves. This escape route turned out to be very important to our ML team, and the requests to create those worker runs have piled up.
To lessen the load on instance administrators and give users more agency over these workers, we have now exposed this system as user worker runs. You can now create worker runs directly through the frontend or the API.
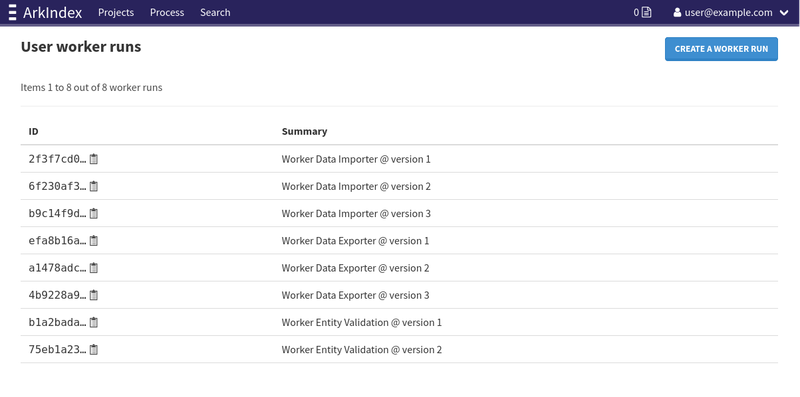
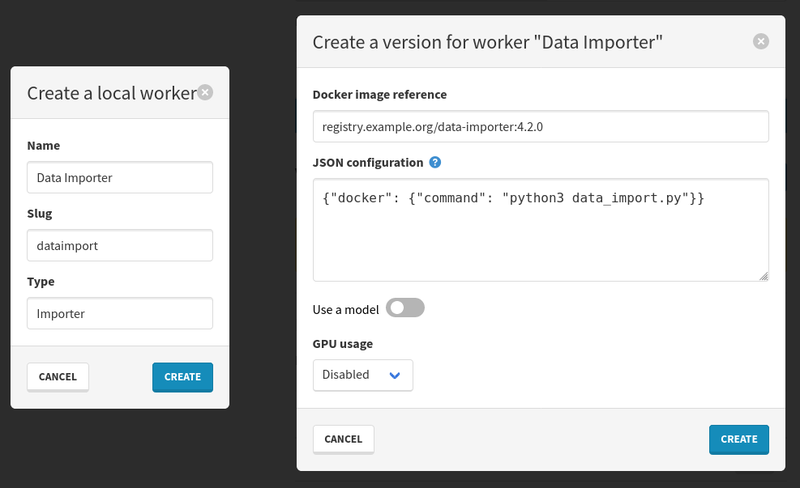
You can also create workers and worker versions. Those normally cannot be executed in normal processes, but their IDs can be used to create worker runs and a specific script as a source of worker results.
You can however specify a Docker image tag when creating a worker version, which lets you import any Docker image as a worker that can be run just like any other worker in a process, as long as the image is available to the Ponos agent.
CLI
The Arkindex CLI has also been updated, mainly to work towards a better GitLab CI integration.
The arkindex process report and arkindex process recover commands have been removed, as they have been replaced by worker activities and the ability to select failed elements from them, and they were no longer working since Arkindex 1.5.0.
The arkindex models publish command now supports publishing Markdown descriptions of models, which can be displayed in the frontend.
The arkindex workers publish now parses version 3 of the YAML configuration files to retrieve all of the worker attributes, which simplifies publishing workers within CI pipelines.
Finally, all CLI commands now support the use of a --gitlab-secure-file argument that retrieves the CLI profiles configuration from a GitLab Secure File, to store the API tokens on multiple instances at once in one file that is easier to manage for project maintainers.
Misc
This release also comes with many bugfixes related to processes, worker activities, and IIIF.
- IIIF and Files processes no longer republish DataFiles as artifacts, saving precious storage space.
- IIIF imports now show a clearer message when an IIIF 3 manifest is imported, as we currently only support IIIF 2.
- The estimated completion time within worker activities now takes into account the use of chunks for distributed processing.
- Fixed various errors on many edge cases on the relative dates shown in worker activities and in the processes list.
- Worker activities now properly display the worker configuration associated with the worker version and model version, without causing error messages to appear.
- Dataset processes with workers that require a GPU can no longer be started without enabling GPU usage, just like Workers processes.
- Workers processes with workers that require a GPU no longer have an initialisation task created when trying to start them without GPU usage.
- Retrying IIIF, Files, or S3 imports no longer causes errors due to duplicated WorkerRuns.
- The
initialisationtask on Workers processes is no longer limited to 32 chunks. - The
Access-Control-Allow-Originheader is now properly configured to allow any IIIF viewer to access the IIIF manifests of public projects.