We are happy to announce that a new Arkindex release is available. You can explore Arkindex and try out the newest features on our demo instance, demo.arkindex.org.
This release has focused on fixing bugs, improving performance and security, and simplification of some fundamental concepts.
Elements management
In the last release, we had introduced a new type_ordering option to the CreateElementParent endpoint to change the way elements were ordered within their parents. In this release, the new type-unaware ordering mode, which was set with type_ordering=False, is now the default.
This now means that elements of multiple types can be ordered before or after one another in a parent element, and that they are no longer sorted by type. This makes managing elements of multiple different types within an element easier, and especially helps with the notion of reading order within elements on the same image.
This change allows for better data integrity and paves the way for even more improvements on element management. Adding or deleting parent elements has also been made faster.
Exports
The SQLite exports have been updated to include worker runs, which are becoming more important to track the origin of Machine Learning results. Transcription orientations are also now included, and the export structure documentation has been updated.
We published a new Python package to help in using Arkindex SQLite exports in other scripts, called arkindex-export. This package relies on Peewee to abstract away the SQL queries, and will allow us to provide functions for common queries to help developers get acquainted with using the exports and process their data faster.
Machine Learning workers
A new concept of datasets has been introduced. Datasets can contain any element from one corpus and will make training Machine Learning workers more reproducible and stable. Those are currently only available through the Django admin or command-line shells as a proof-of-concept, and they will be more easily available in future releases.
More changes related to workers are included in this release:
- The assigned GPU is now kept on a task even after it finished, making it easier to troubleshoot failures on workers that use GPUs after the fact.
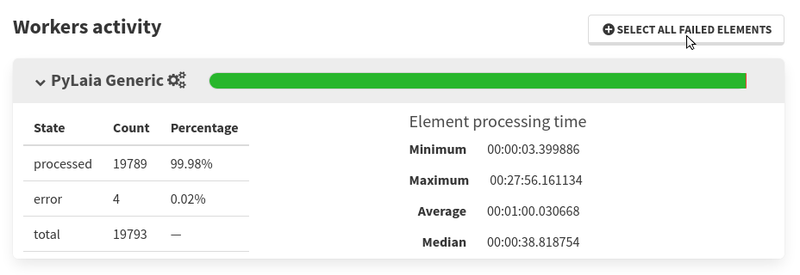
- It is now possible to select elements whose worker activities are in an error state.
- Workflow recipes have been removed. Recipes were an intermediary step to starting processes that were never exposed to users and added a lot of complexity. This removal significantly reduces database usage when starting or retrying processes.
Security
With the introduction of the new Ponos authentication method in version 1.4.1, the permissions for workers have been updated. Sending a worker_run_id on any Machine Learning result (element, classification, metadata, transcription, entity or transcription-entity link) can now only be done through a worker. This worker run ID must be a part of the process of the currently running worker.
The only exception to this are for worker runs of the user's local process, which can be created by instance administrators using the arkindex fake_worker_run command. Local worker runs are meant as an escape hatch to help with one-time scripts that are not worth being implemented as workers, and can be used by regular users.
We made the API documentation clearer on the relevant endpoints to help API consumers better understand the changes.
Workers that have not been updated to version 0.3.3 of base-worker can still partially function with the deprecated authentication system, but some features will no longer work, including worker activities.
Misc
- A new license key system has been introduced to help with on-premise deployments.
- The deletion of worker activities when deleting a corpus has been optimized, leading to a significantly faster deletion, especially for empty corpora.
- Filtering elements by element type has been made faster on large instances with numerous corpora and element types.
- Fixed an error when renaming a worker configuration to the name of an existing configuration.
- Fixed an error that prevented deleting a finished corpus reindexation job.
- Fixed an error that prevented listing the artifacts of a process.
- Fixed an error when sending invalid values to the
RemoveSelectionendpoint. - Fixed an error when retrieving a model version without having permission to do so.
- The
slim_outputattribute on the CreateElement endpoint is now deprecated, as it does not bring any significant performance improvement. - The deprecated
type_namefield has been removed fromCreateEntity,UpdateEntityandPartialUpdateEntity. Please use thetype_idfield instead.