We are happy to announce that a new Arkindex release is available. You can explore Arkindex and try out the newest features on our demo instance, demo.arkindex.org
Processes
This release has largely focused on many aspects of processes in Arkindex, from bug fixes to introducing a new kind of process.
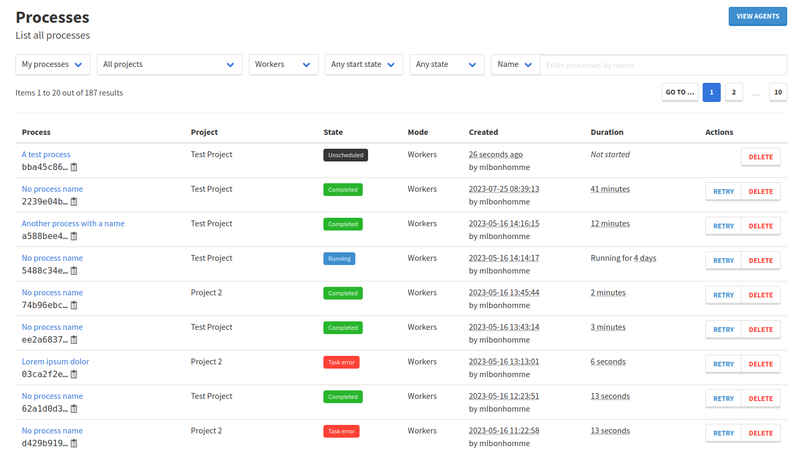
Redesigned process list
The process list has been redesigned to give more space to important attributes and make it easier to find your processes:
- Process names are now more emphasized than IDs.
- Process states use the same colors as in the process status page, to more easily distinguish processes by their state.
- The date column has been split in two, to allow displaying when process was created, by whom, and for how long it ran; or for how long it is still running.
- The Configured filter has been replaced with a Started filter, allowing to look for processes that have already started or have not yet.
Redesigned process configuration
The configuration page for Workers processes has also been redesigned. Newer features such as models and configurations had started to outgrow the previous design, and quickly became just as important when configuring processes than workers themselves. The new page shows worker versions, model versions and worker configurations in a table. Links are provided to view the details of each of them.
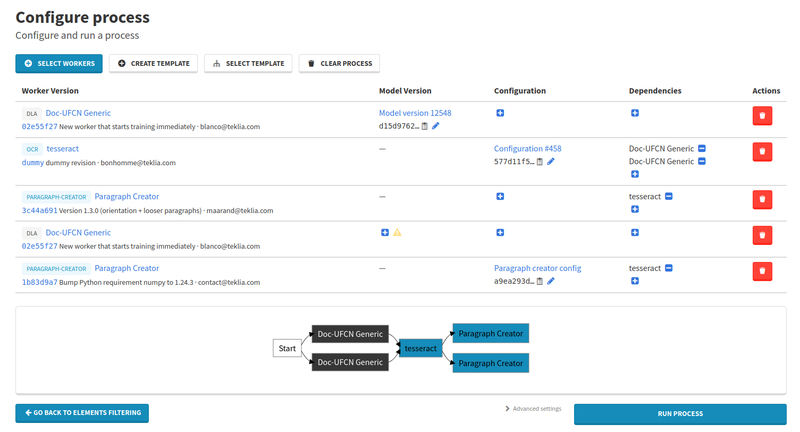
Additionally, this configuration page is now still accessible when a process has already started, letting you see how a process was configured even after it ran. The same table is also shown on template processes for consistency.
Better support for generic workers
The process configuration redesign has allowed us to allow adding the same worker version multiple times to a process, with different model versions and worker configurations, without having to run separate processes. This greatly simplifies working with generic workers that accept many different models.
This change has required us to also update the UpdateWorkerActivity endpoint, used by workers to report whether they started, finished or failed to process an element. This endpoint used to take in a worker version ID to tell which worker was reporting its state on the process. Using worker version IDs is now still supported, but deprecated, and it will not work if the same worker version is used multiple times in a process. Workers should be updated to send worker run IDs instead, which will distinguish them uniquely in such processes.
Additionally, to help in managing the outputs of those generic workers, worker results deletions now support filtering by model version, or lack thereof. The worker results deletion modal has been updated to use the same design as for the new process configuration page and support this new filter.
Dataset processes
A new process mode has been introduced to support running processes on datasets instead of elements.
A Dataset process behaves just like a Workers process. However, it does not create an initialisation task and does not provide an elements.json file to workers: workers are expected to request what they need on datasets from new dataset APIs that we are starting to introduce.
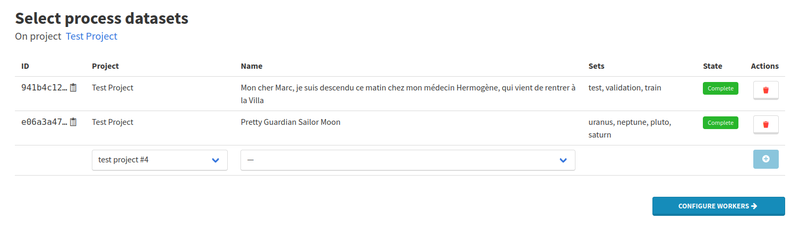
This process is meant to allow splitting a model training into multiple steps and make training faster. A first worker could build a dataset, generating an archive with pre-processed images or any other data that training a model requires. A second worker could train a new model from this preprocessed data. A third worker could run this new model version on a test or validation set to get some insights on how this model version is performing.
Those three steps could run independently, allowing to pre-process a dataset only once, train multiple models at once, etc., and make iterating on model training faster. In the long term, we plan on removing Training processes and replacing them with this new more flexible approach.
For now, this is not fully supported by our workers, but this release will allow to start testing this new system and get feedback from our Machine Learning teammates.
Status tracking
To make it easier to follow long processes, the creator of a process now receives an email when a process finishes, be it successfully or not. This email includes the state of each of its tasks and a link to the process status page to learn more. Those emails are not sent for Repository processes, as they run often and automatically and would otherwise flood the inboxes of Git credential owners.
Since we now allow the same worker version multiple times, worker activities have been updated to include model versions. They already supported worker configurations. Their statistics now also include an estimated completion time for processes that have not yet finished, and the durations are displayed in a more human-friendly way.
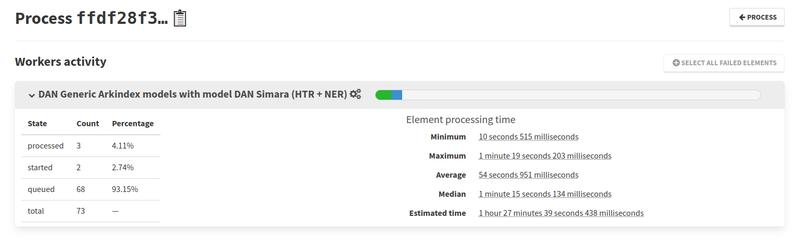
Task execution
This release includes quite a lot of bug fixes, especially on Ponos agents and tasks:
- Restarting a Ponos task using the Restart task button now resets both the agent and the GPU, avoiding issues with tasks that used GPUs.
- Task and Artifact URLs are no longer available in the APIs, as the URLs can be reconstructed from IDs instead or used as parameters in an OpenAPI client.
- The
WORKER_VERSION_IDenvironment variable has been removed from Ponos tasks created for workers, as theARKINDEX_WORKER_RUN_IDvariable replaces it. - Tags have been removed from tasks. Those were part of an old system that filtered the tasks accepted by agents and that we had removed in Arkindex 0.14.4.
- Fixed HTTP 500 errors that occurred when a task's logs were zero bytes in length.
- The Ponos agent now properly handles multiple Docker registries at once in its configuration without requiring multiple restarts.
- Ponos tasks can now inspect themselves via the
RetrieveTaskFromAgentendpoint. - Ponos agents can now access worker runs via
RetrieveWorkerRun, only for processes where they have a task assigned to them. - Tasks are now properly editable in the Django admin, without their artifacts causing validation errors.
Repository imports
Our Repository processes now support version 3 of .arkindex.yml. YAML configurations that use version 3 will cause the process to stop without importing anything, as this version is meant to allow publication from within a CI pipeline using the CLI's arkindex workers publish command.
This version does not require a type to be set, as it will always be worker, and does not require docker.build to be set since Docker builds will be managed in CI jobs directly.
In the long term, we plan on dropping Repository processes and entirely leaving the responsibility of building and publishing workers up to the workers themselves via their CI pipelines, to reduce the load on Ponos agents and better support workers published on multiple Arkindex instances.
Additionally, retrying a Repository process now only recreates the initial task, fixing errors that occurred since Arkindex 1.5.0.
Other changes
- WorkerRun summaries are now available in all WorkerRun API endpoints.
- The
use_cacheattribute of processes is now available inRetrieveWorkerRunto make cache detection simpler in workers. - Template processes can no longer be created from or applied to processes with modes other than
WorkersorDataset. arkindex cleanupnow ignores artifacts and tasks linked to any dataset.- S3 download URLs for DataFiles are now available to IIIF imports, not just file imports.
- Starting a process now checks that any worker version with a user configuration with required fields and no default values have their required fields set in a selected worker configuration.
- Worker runs can no longer be added as a dependency of another multiple times.
- The finished timestamp on processes is now properly set when a process fails with some tasks still staying unscheduled.
Datasets
With the introduction of Dataset processes, we also started introducing the necessary features to make them easier to work with.
A new ListDatasetElements API endpoint is now available to list the elements on a dataset. It is not yet available in the frontend.
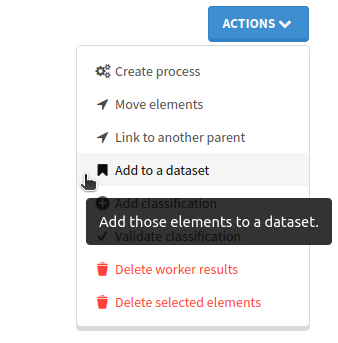
A new CreateDatasetElementsSelection API endpoint is now available to add elements to a dataset from a selection, and it is available as a new option in the frontend's selection page:
CLI
The Arkindex CLI has also been updated. Release 0.3.0 updates all of the export commands to use the Arkindex Export library, making it easier to work with the Arkindex SQLite exports using Peewee. This will make the export commands easier to maintain and less prone to bugs.
This change means we are removing the arkindex_cli.commands.export.db module, which was a private API that got used by various external scripts. Those scripts should be rewritten to also use the export library.
The CLI now also includes a selection import command to quickly add a list of element IDs to your selection, which can be useful when working with element IDs from SQLite exports or other sources and wanting to use them in Arkindex again.
The arkindex workers publish command, which will start to replace Repository processes, now uses GitLab CI variables instead of inspecting a Git repository when available. In the future, the command will also support version 3 of .arkindex.yml.
Frontend bug fixes
We made some significant progress on our work towards migrating our frontend to TypeScript and migrating from Vuex to Pinia to keep up with changes in the Vue.js ecosystem. Those changes normally have very little effect outside of our own team, but this switch invites us to verify our own documentations and helps us catch bugs.
Thanks to our progress this summer, we fixed a bug that prevented a model version's configuration from displaying in the model version details page, and we fixed some parts of the API documentation, particularly SearchCorpus, RetrieveAgentActions, ListOAuthCredentials and all endpoints related to model versions and tasks.
Other fixes include:
- Very long modal titles are now truncated to avoid overflowing the screen.
- The Ponos agents list, accessible via the View agents button in the process list, now sorts agents by hostname instead of how recently they reported their state to Arkindex, preventing the list from being unexpectedly reordered.
- The Actions and Display menus of the header shown in the element details page are now visible immediately, even when neighbors have not loaded yet.
- The folder picker, a modal shown in various places such as the training process configuration page or the Move element action, now shows a message when there are no folders to pick from, instead of being completely empty.
Misc
- The
ListElementNeighborsAPI has been updated to return a simpler API response that better matches how it is being used. It no longer uses pagination. - The delay during which a new export cannot run again on a project after another one was successful, which defaults to six hours, can now be configured by instance administrators to help users work with faster evolving projects.
- Projects and element types can now be marked as indexable in Solr via the Django admin, even when there are a lot of exports or memberships associated with the project.