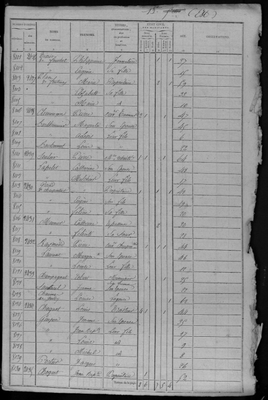
This paper presents a complete processing workflow for extracting information from French census lists from 1836 to 1936. These lists contain information about individuals living in France and their households. We aim at extracting all the information contained in these tables using automatic handwritten table recognition. At the end of the Socface project, in which our work is taking place, the extracted information will be redistributed to the departmental archives, and the nominative lists will be freely available to the public, allowing anyone to browse hundreds of millions of records. The extracted data will be used by demographers to analyze social change over time, significantly improving our understanding of French economic and social structures. For this project, we developed a complete processing workflow: large-scale data collection from French departmental archives, collaborative annotation of documents, training of handwritten table text and structure recognition models, and mass processing of millions of images. We present the tools we have developed to easily collect and process millions of pages. We also show that it is possible to process such a wide variety of tables with a single table recognition model that uses the image of the entire page to recognize information about individuals, categorize them and automatically group them into households. The entire process has been successfully used to process the documents of a departmental archive, representing more than 450,000 images.
Check out our poster presented at ICDAR2024 here.