Le projet Socface est un projet de recherche collaborative financé l'Agence Nationale de la Recherche ayant pour objectif la transcription automatique par Intelligence Artificielle de tous les recensements français entre 1836 et 1936. Le projet est coordonné par l'Institut Nationale d'Etudes Démographiques (INED) avec pour partenaires l'Ecole d'Economie de Paris, le Service Interministériel des Archives de France (SIAF) et TEKLIA.
Collecte des images
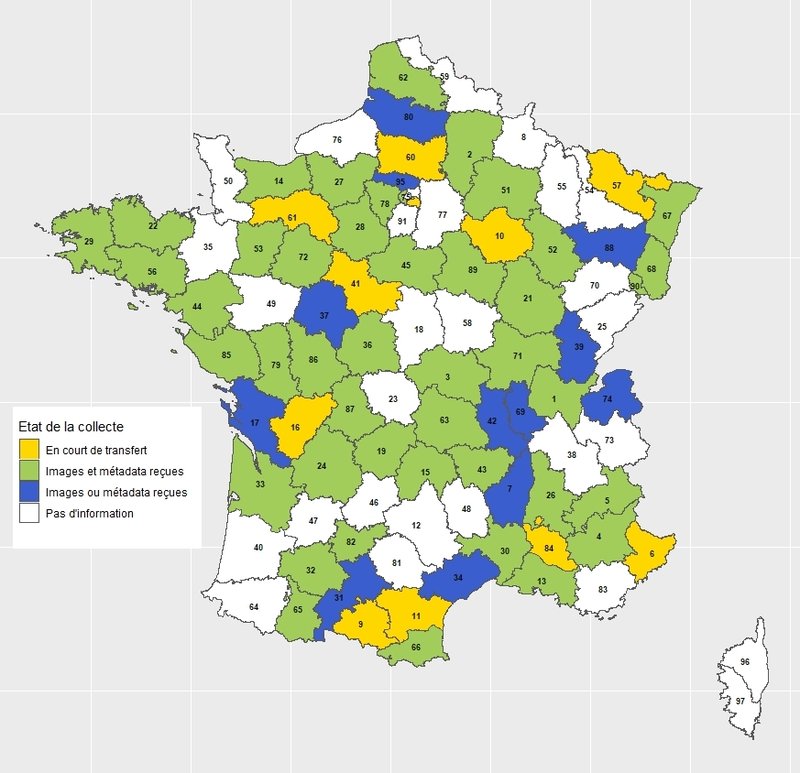
Le premier défi du projet Socface est la collecte de l'intégralité des images de recensements auprès des services d'archives. La progression de cette collecte est disponible sur le site Socface. La participation des différents services d'archive est en général très enthousiaste. Une fois reçues les images et les méta-données associées, il faut intégrer et organiser toutes ces données dans la plateforme Arkindex, grâce à un important travail de normalisation.
Transcriptions collaboratives
Au cœur de tous les projets d'intelligence artificielle se trouvent les données nécessaires pour entraîner les machines. Ces données doivent être à la fois produites en grande quantité et de qualité. Elles sont donc toujours produites par des humains. Le projet Socface n'échappe pas à la règle et 11 campagnes de transcription collaborative ont été lancées fin février sur la plateforme Callico.
Pour chaque campagne, 100 pages ont été sélectionnées aléatoirement dans toutes les images du service d'archive concerné. Les lignes correspondant à chaque individu ont ensuite été automatiquement détectées et ces lignes sont présentées pour la saisie dans Callico. Ce sont donc entre 2500 et 3000 lignes par campagne qu'il faut transcrire, en suivant des instructions très précises et spécifiques.
Progression des campagnes
Une quarantaine de volontaires contribue aux différentes campagnes, avec une petite dizaine d'actifs réguliers. La progression des campagnes est variée, en fonction du nombre et de l'activité des volontaires :
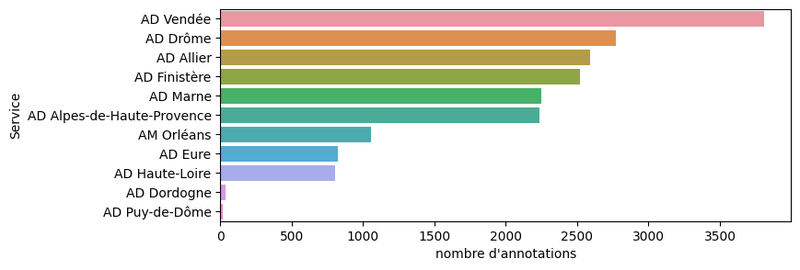
Certaines campagnes sont en double annotation, ce qui explique un nombre d'annotations supérieur à 3000.
Durée d'annotation
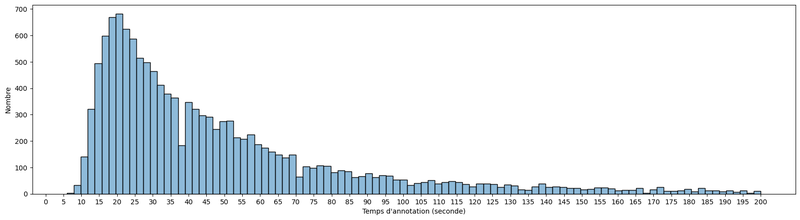
Le temps médian d'annotation est de 36 secondes. Cependant, cette durée est très variable en fonction des images et des annotateurs. Souvent, pour bien faire, il est nécessaire de faire des recherches pour vérifier un nom ou un lieu.
Données saisies
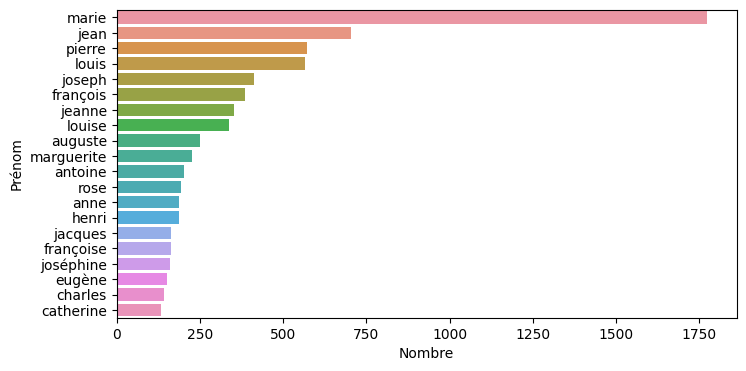
Un analyse des valeurs saisies les plus fréquentes permet de confirmer la qualité des données : les prénoms les plus fréquents sont ceux attendus:
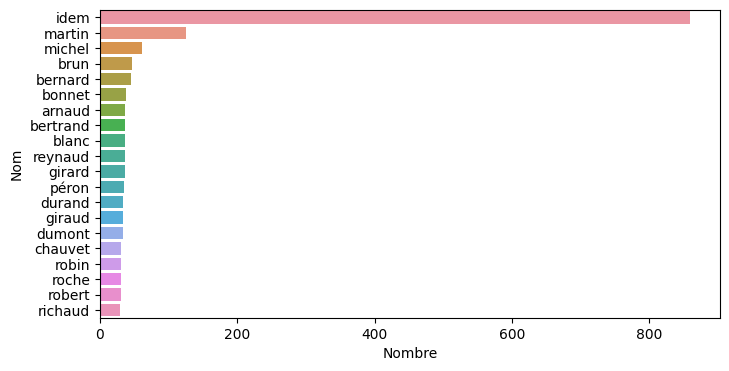
Pour les noms, la mention "idem" est très fréquente, comme attendu, car les instructions indiquent qu'il faut saisir cette mention et ne pas remplacer par la valeur en référence.
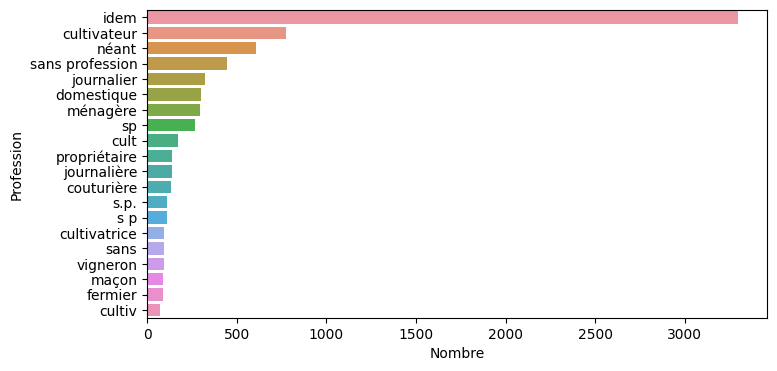
Pour les professions, les cultivateurs sont les plus fréquents, sous différentes formes, qu'il faudra normaliser pour réaliser des analyses statistiques.
Entraînement du modèle IA
Le modèle d'Intelligence Artificielle permettant la transcription automatique des listes a été mis au point. Une première version a été entraînée sur les données de Paris fournies par le projet POPP ainsi que sur les transcriptions collaboratives réalisées sur le site des archives du Loiret. Les transcriptions issues des campagnes Callico seront bientôt ajoutées à l'ensemble d'entraînement.

Les premières données de transcription automatique à l'échelle de départements entiers seront livrées aux chercheurs cet été.
Merci !
Merci à tous les participants du projet Socface !