Les instruments de recherche aux Archives Nationales
Les Archives Nationales ont pour mission de collecter, trier, décrire, conserver, restaurer, communiquer et valoriser les archives publiques des administrations centrales de l'État, les archives des notaires de Paris et les archives privées d'intérêt national.
Afin de permettre à leur public de rechercher et de consulter les fonds d'archives, les Archives nationales produisent des instruments de recherche (répertoires, catalogues, inventaires) qui regroupent les principales métadonnées des dossiers ou documents : code de référence/identifiant, titre, date, provenance, contenu particulier, taille, volume, références à d'autres archives ou ressources bibliographiques, indexation de thèmes et de noms de lieux ou de personnes, etc.
La conversion des instruments de recherche manuscrits
Si les instruments de recherche actuels sont produits directement sous forme numérique (XML EAD), les Archives Nationales disposent également d'instruments de recherche anciens, produits entre la fin du XVIIIe siècle et la première moitié du XXe siècle. Ils sont soit imprimés, soit dactylographiés, soit manuscrits. Beaucoup d'entre eux ne sont pas encore accessibles en ligne, et parfois même pas en salle de lecture, alors qu'ils concernent des fonds d'archives importants, notamment ceux du Moyen Âge et de l'Ancien Régime. Ces derniers ont été les premiers à être décrits par les archivistes au XIXe siècle, et sont donc ceux pour lesquels la proportion d'instruments de recherche traditionnels est la plus élevée.

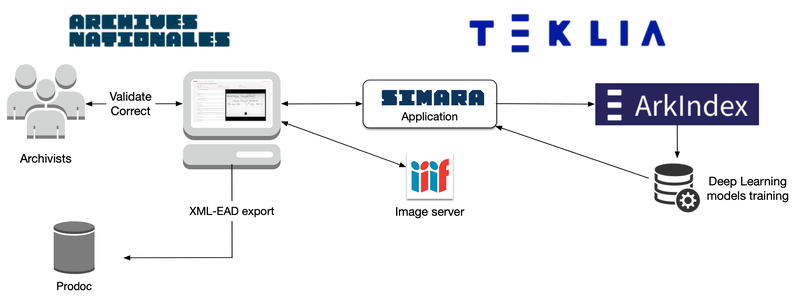
Afin d'accélérer la mise en ligne de ces anciens inventaires, les Archives nationales ont choisi TEKLIA pour développer une application d'aide à la rétroconversion des instruments de recherche manuscrits. Cette application s'est appuyée sur l'expertise de TEKLIA en matière de reconnaissance d'écriture manuscrite pour automatiser une grande partie de la transcription des images.
Comment réduire la charge de la production manuelle d'annotations ?
L'utilisation de modèles de Deep Learning nécessite le plus souvent la mise en œuvre d'une campagne d'annotation afin de produire les données annotées nécessaires à l'entraînement des modèles. Dans le cadre du projet SIMARA, la transcription manuelle des notices nécessite l'aide d'archivistes, car la lecture et l'interprétation de leur contenu manuscrit requiert des compétences paléographiques et archivistiques. Cependant, il n'était pas envisageable de mobiliser des archivistes pour produire une grande quantité de transcription manuelle. TEKLIA a donc décidé de ne pas réaliser de campagnes d'annotation, mais d'entraîner les modèles de Deep Learning directement à partir du résultat de la conversion des notices dans l'application par les archivistes. Les archivistes ont simplement utilisé l'application SIMARA pour effectuer la conversion des notices et ont en même temps généré des données d'entraînement pour les modèles.

Entraînement des modèles de Deep Learning avec Arkindex
Après que TEKLIA a développé l'application web SIMARA, les archivistes ont commencé à saisir des informations sur les images des instruments de recherche de différents fonds d'archives. Certaines actions ont été automatisées dans l'interface, comme la normalisation des dates ou la validation des entités (noms de lieux) à partir d'un référentiel XML.
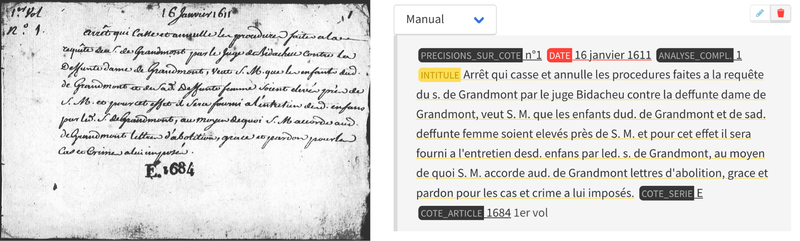
Après avoir saisi environ 200 notices pour chaque collection, TEKLIA a transféré les données de l'application SIMARA vers Arkindex afin d'entraîner les modèles de reconnaissance d'écriture manuscrite (HTR) et d'extraction d'entités (NER). Il est important de noter que les modèles ont été entraînés sans annotation manuelle de la position des informations sur l'image, une étape qui prend généralement beaucoup de temps. Au lieu de cela, le modèle a été entrainé directement à partir des saisies des archivistes dans le formulaire de l'interface web SIMARA. Aucune annotation spécifique n'a été nécessaire pour entraîner le modèle.
Grâce à l'utilisation du pré-entraînement, les performances des modèles HTR/NER ont été très bonnes même avec un petit nombre de données annotées (880 images annotées). Un taux d'erreur sur les caractères de 12% a été mesuré sur un ensemble de test indépendant, mais cette valeur est surestimée en raison des différences d'ordre de lecture entre l'annotateur et la machine. En pratique, les archivistes ont été impressionnés par la qualité de la transcription automatique. La date et le code de référence sont reconnus parfaitement sur la quasi-totalité des fiches. Les abréviations telles que psse pour paroisse ou c.d.m. pour contrat de mariage sont automatiquement développées par le modèle de reconnaissance. Le modèle a également été capable de gérer différents styles d'écriture et conditions de numérisation.

Saisie de données assistée par HTR
Le modèle de reconnaissance/extraction a ensuite été appliqué aux documents non encore saisis par les archivistes et le résultat a été envoyé à l'application SIMARA comme base pour la saisie manuelle. Grâce à la transcription automatique, les archivistes n'ont plus qu'à valider et éventuellement corriger le résultat de la reconnaissance. Les informations sont déjà placées dans les champs correspondants du formulaire.

Mise en production
SIMARA est maintenant utilisé en production aux Archives nationales pour la conversion des instruments de recherche manuscrits, assistée par la reconnaissance automatique de l'écriture manuscrite et l'extraction d'informations. Un ensemble de 121 instruments de recherche, présentés soit sous forme de registres, soit sous forme de fiches, représentant un total d'environ 100 000 pages et 800 000 fiches, seront à terme convertis à l'aide de l'application SIMARA.

L'application SIMARA représente pour nous un grand pas en avant pour la conversion numérique de nos plus anciens instruments de recherche. Elle tire parti des technologies de l'IA pour nous faire gagner un temps considérable, puisque nous n'avons plus à réaliser les tâches les plus fastidieuses comme la saisie de l'intégralité du texte original ou l'encodage manuel des données en XML. Ces tâches étaient auparavant réalisées séparément alors que SIMARA les exécute en même temps. Nous avons des instruments de recherche très importants, tels que des fichiers contenant plus de 100.000 enregistrements chacun. SIMARA nous aide à traiter ces documents, car nous nous concentrons désormais uniquement sur la modélisation des données et la validation des enregistrements une fois qu'ils sont convertis. Ce projet a été financé par le plan national de soutien du Premier ministre. Il était considéré comme l'un des plus innovants, mais ce soutien impliquait un développement rapide. L'interface SIMARA a été développée et mise en production en 7 mois. Même lorsqu'elle n'était pas en production, nous avons néanmoins pu commencer à fournir à TEKLIA des données d'apprentissage, et nous avons donc reçu les transcriptions automatiques assez rapidement après la sortie de l'application et sa validation par nos soins. Nous sommes très satisfait de notre partenariat avec TEKLIA. Nous avons été impressionnés par la capacité de l'IA à traiter des écritures difficiles provenant de différentes périodes et à identifier le type d'information pour l'encoder au bon endroit. Nous considérons que le traitement des archives avec l'IA améliorera à l'avenir les services que nous pouvons offrir à nos utilisateurs, car nous pourrons enrichir les métadonnées non seulement des instruments de recherche, mais aussi des archives elles-mêmes.
L'application est hébergée et maintenue par TEKLIA.